Introduction
In today’s data-centric world, making informed decisions is vital for businesses. To support this, Amazon Web Services (AWS) offers a robust data warehousing solution known as Amazon Redshift. Redshift is designed to help organizations efficiently manage and analyze their data, providing valuable insights for strategic decisions. In this blog post, we will delve into AWS Redshift, exploring its core features, benefits, and typical use cases.
Understanding Amazon Redshift
Amazon Redshift is a fully managed, cloud-based data warehousing service. Tailored for data warehousing and analytics, it offers high performance, scalability, and cost-effectiveness. Redshift is a solid choice for organizations looking to analyze large datasets and derive insights efficiently.
Client applications
Business intelligence (BI) reporting, data mining, and analytics tools, as well as a variety of data loading and ETL (extract, transform, and load) tools, are all integrated with Amazon Redshift. Since PostgreSQL is an open standard and Amazon Redshift is built on it, most current SQL client apps may be used with little to no modification. See Amazon Redshift and PostgreSQL for details on significant distinctions between the two databases.
Clusters
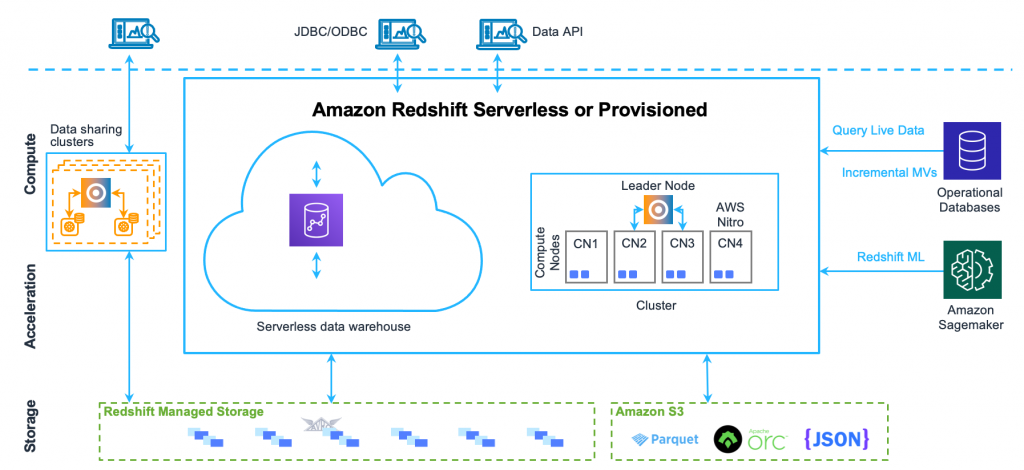
A cluster is an essential part of an Amazon Redshift data warehouse’s infrastructure.
There may be one or more computational nodes in a cluster. An additional leader node directs the compute nodes and manages external communication if a cluster is provisioned with two or more compute nodes. Only the leader node is the only direct interaction your client application has. To outside applications, the compute nodes are transparent.
Leader node
The leader node controls all communication with compute nodes as well as communications with client programs. In particular, the succession of steps required to get responses for complicated queries is parsed and developed into execution plans. The leader node compiles code based on the execution plan, distributes the code to the compute nodes, and distributes a piece of the data to each compute node.
Only when a query refers to tables kept on the compute nodes does the leader node disseminate SQL queries to the compute nodes. Only the leader node handles all other queries. Certain SQL operations can only be implemented by Amazon Redshift on the leader node. Any query using one of these functions will result in a failure.
Compute nodes
The code for each component of the execution plan is assembled by the leader node and sent to each compute node. The leader node will then aggregate the final results from the compute nodes’ execution of the produced code.
The compute node determines which node has which dedicated CPU and memory. As your workload expands, you can upgrade the node type, add more nodes, or do both to enhance a cluster’s computing capacity.
Redshift Managed Storage
Redshift Managed Storage (RMS), a separate storage tier, is where data warehouse data is kept. Using Amazon S3 storage, RMS gives you the option to scale your storage to petabytes. You may size your cluster based solely on your computing requirements thanks to RMS’s ability to scale and pay for computing and storage independently. As a tier-1 cache, it automatically employs high-performance SSD-based local storage. Additionally, it makes use of optimizations such as workload patterns, data block temperature, and data blockage to deliver great performance while scaling storage to Amazon S3 automatically as necessary.
Databases
One or more databases can be found in a cluster. The computing nodes house user data. Your SQL client interacts with the leader node, which then plans the query execution on behalf of the compute nodes.
Since Amazon Redshift is an RDBMS (relational database management system), it can work with other RDBMS applications. Amazon Redshift is optimized for high-performance analysis and reporting of big datasets, even though it offers the same capability as a traditional RDBMS, including online transaction processing (OLTP) activities like inserting and removing data.
PostgreSQL forms the basis of Amazon Redshift. You must consider a number of extremely significant differences between Amazon Redshift and PostgreSQL when you plan and create your data warehouse applications.
Node slices
Slices of a computing node are created. A portion of the node’s memory and disc space are allotted to each slice, which uses those resources to process a piece of the workload given to the node. The workload for any queries or other database activities is divided among the slices by the leader node, which also oversees data distribution to them. The process is then finished in parallel by the slices.
The cluster’s node size affects the amount of slices per node. Go to About clusters and nodes in the Amazon Redshift Management Guide for more details on the amount of slices for each node size. You can choose to designate one column as the distribution key when creating a table. As soon as the table is filled with
Key Features of Amazon Redshift
- Columnar Storage: Redshift stores data in columns, which enhances query performance and reduces I/O operations.
- Massively Parallel Processing (MPP): Redshift distributes query processing across multiple nodes, ensuring scalability as data and query complexity increase.
- Automatic Compression: Redshift automatically compresses data, reducing storage costs and improving query performance.
- Data Ingestion: It supports various data loading options, including batch loading and direct data transfer from sources like Amazon S3.
- Concurrency Scaling: Redshift can add extra capacity to handle concurrent queries during peak workloads.
- Security: Redshift offers robust security features, including encryption at rest and in transit, role-based access control, and VPC isolation.
- Integration: It seamlessly integrates with popular BI tools and data visualization platforms.
- Automated Maintenance: AWS manages backups, patching, and scaling, reducing operational overhead.
Benefits of Using Amazon Redshift
- Scalability: Redshift scales from gigabytes to petabytes, accommodating business growth.
- Cost-Effective: Its pay-as-you-go pricing model ensures cost efficiency.
- High Performance: Redshift’s MPP architecture and columnar storage deliver fast query performance.
- Ease of Use: The SQL-based interface is accessible to data professionals and business users.
- Data Integration: Redshift integrates with AWS services and supports popular ETL tools.
- Security and Compliance: Redshift meets security and compliance standards, suitable for sensitive industries.
Common Use Cases
- Business Intelligence: Redshift powers data warehouses for BI dashboards and reports.
- Data Analytics: It’s used for complex analytics, including customer segmentation and market analysis.
- Log Analysis: Redshift analyzes log data for insights into system performance and security.
- Data Lake Integration: It serves as an analytics layer for data lakes.
- Time Series Data: Suitable for IoT and real-time monitoring applications.
Conclusion
Amazon Redshift is a powerful data warehousing solution that enables organizations to extract value from their data efficiently. It offers scalability, cost-efficiency, and robust security, making it a compelling choice for data-driven businesses. With seamless integration and automation, Redshift simplifies the data analytics process, empowering organizations to make informed decisions and stay competitive in their industries.
● Challenges in managing and analyzing large amounts of data:
- Data silos: Data is often siloed in different departments or systems, making it difficult to get a complete view of the data.
- Data quality: Data can be dirty or inconsistent, which can lead to inaccurate insights.
- Data security: Data needs to be protected from unauthorized access and misuse.
- Data scalability: As data grows, it can become difficult to manage and analyze on traditional systems.
● How Amazon Redshift can help address these challenges:
- Redshift’s columnar storage and MPP architecture can improve query performance, even on large datasets.
- Redshift’s automatic compression can help to reduce storage costs.
- Redshift’s security features can help to protect data from unauthorized access.
- Redshift’s scalability can help to accommodate the growth of data.
● Specific examples of how businesses have used Amazon Redshift:
- A retailer used Redshift to analyze customer purchase data to improve its marketing campaigns.
- A financial services company used Redshift to analyze trading data to identify potential fraud.
- A healthcare provider used Redshift to analyze patient data to improve the quality of care.
● Additional use cases for Amazon Redshift:
- Fraud detection
- Predictive analytics
- Machine learning
- Time series analysis
- Geospatial analysis
● Upcoming features and enhancements for Amazon Redshift:
- Support for more data types
- Improved performance for complex queries
- New security features
- Integration with more AWS services