Data migration is a crucial process for modern organizations looking to harness the power of cloud-based storage and processing. The blog will examine the procedure for transferring information from MongoDB, a well-known NoSQL database, to Amazon S3, an elastic cloud storage solution leveraging PySpark. Moreover, we will focus on handling migrations based on timestamps to ensure data integrity and execute both full and incremental loads seamlessly.
Understanding Data Migration and the Timestamp-based Approach
Data migration requires the transference of information from one storage system to a different one while safeguarding its virtue and decreasing data loss to the fullest extent possible. Adopting a timestamp-based approach allows us to migrate data incrementally by identifying changes made since the last migration.
Preparing the Environment
Prior to initiating the migration process, we must confirm that the appropriate instruments are available:
● MongoDB is installed and running with the data you want to migrate.
● PySpark and the MongoDB Connector for PySpark installed.
● An AWS S3 bucket and valid AWS credentials are set up to access it.
● Establishing the Connection to MongoDB
First, establish a connection to MongoDB using the MongoDB Connector for PySpark. Create a PySpark DataFrame from the MongoDB collection, enabling us to handle data in a tabular format efficiently.
Data Extraction with Timestamps
To achieve incremental migration, we must track the timestamps of records during the extraction process. Extract data from MongoDB with an added timestamp filter to retrieve only the new or updated records since the last migration.
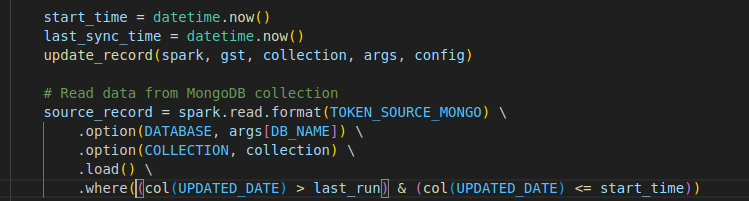
Transforming Data
Data migration often requires data transformation to match the target schema or to perform data cleansing. Utilize PySpark’s transformation functions to manipulate the DataFrame if necessary.
Full Load vs. Incremental Load
At this point, we should distinguish between full and incremental loads:
● Full Load: For the initial migration or data reprocessing, we migrate all data from MongoDB to S3.
● Incremental Load: For subsequent migrations, we only migrate data with timestamps later than the last migration timestamp. Save the timestamp of the latest record migrated to MongoDB or external storage to keep track of the last migration.
● Storing Timestamps for Incremental Load
To ensure data integrity during incremental loads, store the timestamps of migrated records in a reliable storage system. This can be a separate collection in MongoDB or a timestamp tracking file in S3.
Handling Data Consistency
Maintaining data consistency is essential during migration. Implement checksums or other data validation techniques to confirm the data’s accuracy in S3 against the data in MongoDB.
Scheduling Incremental Migrations
To automate incremental migrations, set up a periodic job that checks for new data in MongoDB using the stored timestamp. This job migrates only the relevant records to S3.
Error Handling and Monitoring
Data migration is a complex process, and issues may occur during the transfer. Implement robust error-handling mechanisms and monitoring tools to identify and resolve errors promptly.
In summarizing the above details
Migrating data from MongoDB to Amazon S3 using PySpark with a timestamp-based approach empowers organizations to maintain data integrity and execute full and incremental loads seamlessly. Adopting this strategy can enable businesses to harness the power of cloud-based storage and data analysis while guaranteeing that their information stays reliable and recent. Whether it’s the initial migration or subsequent incremental loads, PySpark’s distributed computing capabilities enable efficient data processing, making data migration a smooth and successful endeavor. However, while migration can provide opportunities, it may pose issues like discrimination and cultural clashes. These issues require attention to ensure the process remains just and impartial for everyone involved.