
From Raw Logs to Structured Data: Working with Datadog Log Pipelines
Introduction
Logs coming from different services often follow inconsistent formats, naming conventions, and structures. This makes it difficult to search, analyze, and correlate events across your systems. Datadog Log Management solves this challenge with Pipelines, Processors, and Standard Attributes, which let you extract key fields, normalize attributes, and enrich log data at scale. In this blog, we’ll walk through how to build a custom pipeline, use the Pipeline Scanner to validate processing, and apply Standard Attributes to unify log data from multiple sources.
Objective
By the end of this blog, you’ll be able to do the following:
- Create and modify a log pipeline from scratch.
- Manage log pipelines and processing using the Pipeline Scanner
- Add Standard Attributes to normalize related attribute names across processed logs.
Processing Logs from Different Sources
- Datadog suggests ingesting logs in JSON format. Yet, not all log sources can be configured to produce logs in this format. Many sources will emit logs as semi-structured text messages. Datadog offers Log Pipelines and Processors to help you extract attributes and enhance log details for these ingested logs.
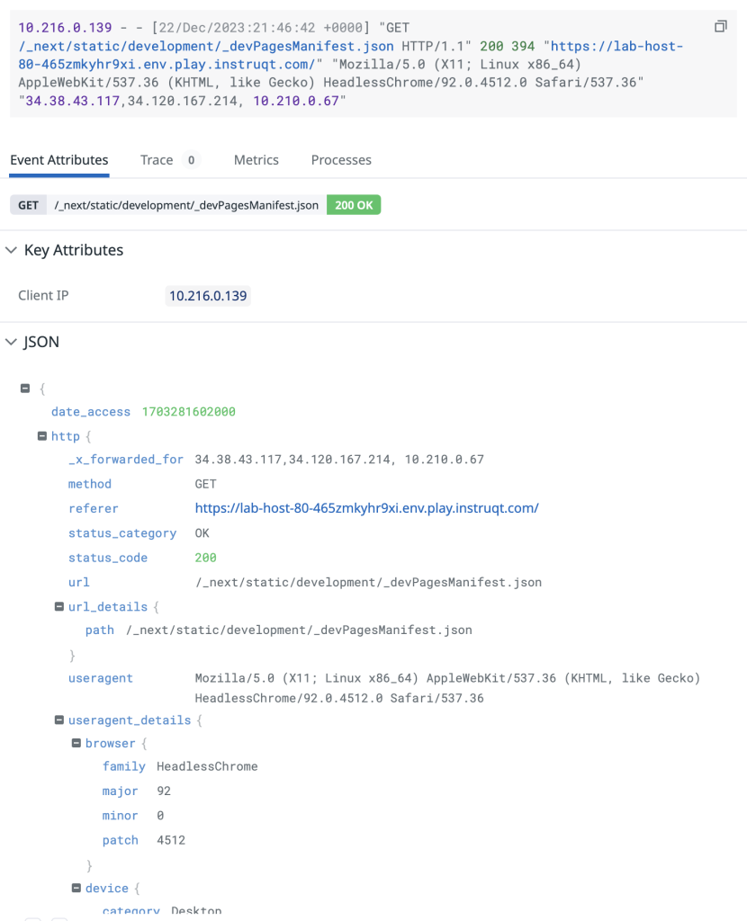
Log processed by an Integration Pipeline.
- Datadog has over 260 to 270 pre-built Integration Pipelines for out-of-the-box processing for logs from common sources, such as popular coding languages, web servers, and cloud services.
- When you configure any of these sources for Log Management in Datadog, you only need to include the source tag or ddsource attribute so that Datadog knows that logs are being ingested from that source.
- Datadog will automatically add the Integration Pipeline to your Pipelines list so that the logs can be filtered into and processed by the Integration Pipeline.
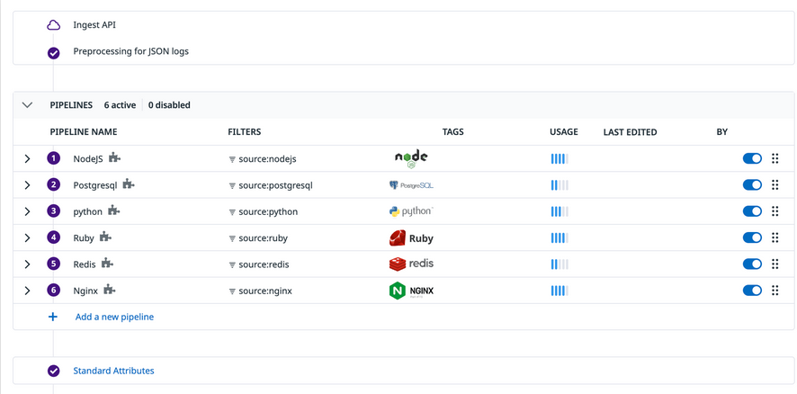
Log processing pathway with Integrations Pipelines in the Pipelines list.
- For log sources that don’t have an Integration Pipeline, you can build log pipelines from scratch to process the logs from these sources as required.
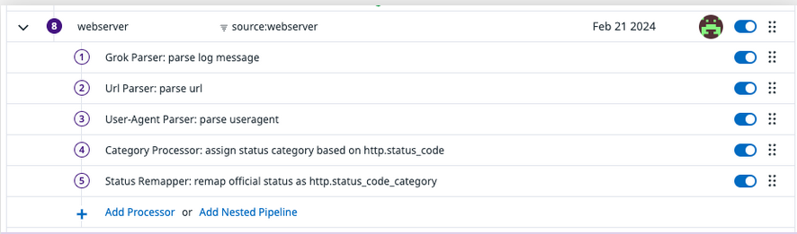
Log pipeline built from scratch.
- As you work with numerous log sources and add more pipelines to your Pipelines list, you’ll need to manage pipelines and optimize how logs are being processed. For example, you’ll want to know if a pipeline is processing the correct set of logs and if the pipeline is processing the logs correctly. You can do this using the Pipeline Scanner.
- You’ll also find that there are common attributes, such as network.client.ip, that are shared across different log sources, such as Nginx, Apache, etc. Many times, these attributes have different names because they come from different sources. For example, client ip for the user’s network can be listed with the attribute name clientip, client, client_ip, or any other name. In Datadog, you can use the Standard Attribute feature to remap the different names of an attribute to one standard attribute name.
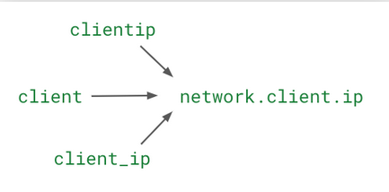
The Standard Attribute feature remaps different names for the same attribute to a standard name.
Pipeline Scanner
- Your organization may have tens to hundreds of pipelines that modify logs from various sources. These pipelines may be set up and managed by different teams for their specific use cases, for example security monitoring, compliance audits, and DevOps.
- As you send your logs to Datadog, you’ll want to make sure that pipeline filters match incoming logs and that pipelines are properly processing the logs. You can use the pipeline scanner to troubleshoot and manage how logs are processed by your log pipelines in real time.
- In the Pipeline Scanner, you can add particular search criteria to trace specific log events and quickly identify which pipelines and which processors in those pipelines are processing the logs that match the search criteria. An example use case of the pipeline scanner is shown below. The column on the left lists logs that match the search criteria source: webserver “[error]”. The first log in the list has been selected, and the column on the right indicates the pipeline and the processors in the pipeline (highlighted in green) that processed the log.
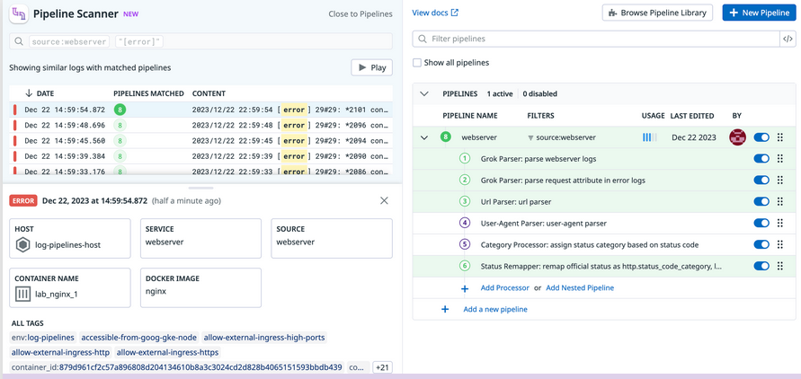
Use the Pipeline Scanner to make sure the expected processors are being applied in a pipeline.
Standard Attributes
- Implementing standard attributes and aliasing is an important part of log processing. A standardized naming convention can unify logs across all sources and teams, allowing you to analyse and search for data from your environments with simplicity
- You can add a Remapper processor in individual pipelines to remap the name of an attribute to the standard name for that attribute. But, if you have logs from different sources with the same attribute and you want to make sure that the attribute has the same name across all logs, you can use a Standard Attribute instead of adding a Remapper processor. A Standard Attribute acts as a global remapper for the attribute and is applied to all logs after the pipeline processing stage.
- For example, you have an environment with ELB and NGINX log sources. ELB and NGINX both produce web access logs with similar details, such as method, status code, and client IP, but they use different naming conventions. This makes it difficult to analyse HTTP traffic over the entire environment. ELB labels client IP addresses as client while NGINX labels them as remote_addr (both are highlighted in pink). The different names makes it difficult to explore a specific client’s activities across both sources.

ELB and Nginx logs for non-standard attribute naming
- You can include a Remapper processor in the pipeline for each of these log sources, or you can add a Standard Attribute, to remap these names to a standard name for this attribute. Datadog uses the prefix network to automatically identify information related to network communication. After remapping, you can use this attribute name to collectively explore client IP address data from these log sources.
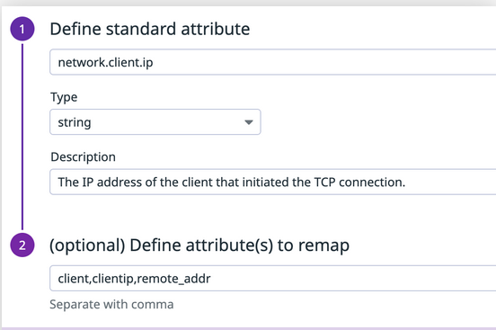
Example of defining a standard attribute in the Standard Attributes list.
- The image below shows logs from both sources after the attributes are remapped (highlighted in green).

ELB and Nginx logs with standard attribute naming. Attribute names that represent the same data attribute are highlighted with the same color.
Conclusion
Datadog offers more than 260 pre-built Integration Pipelines to process logs from common sources. You can easily clone these pipelines and modify them as needed. However, at times you may need to build custom log pipelines from scratch to process semi-structured logs from uncommon sources.
To make log analysis more consistent, you can also use Standard Attributes to remap common attributes across logs to have standard attribute names to be able to search and analyze log data from different log sources. Combined with Pipeline Scanner, you can ensure pipelines are running correctly and troubleshoot processing issues in real time.
By applying these methods, you can improve log quality and consistency and also make monitoring, troubleshooting and cross-team collaboration faster and more effective.
You’re now able to do the following:
- Create and modify a log pipeline from scratch.
- Manage log pipelines and processing using the Pipeline Scanner.
- Add Standard Attributes to normalize related attribute names across processed logs.


