Written by Tushar Raj Verma & Abhishek Kumar Upadhyay
Deep Convolutional Neural Networks have become the state of the art methods for image classification tasks. However, one of the biggest challenges is that they require a lot of labeled data to train the model. In many applications, collecting this much data is sometimes not feasible. One-Shot Learning aims to solve this problem. To understand One-Shot Learning, we first need to understand Siamese networks.
Siamese Networks
This is a type of model network architecture that contains two or more identical subnetworks which are used to generate feature vectors(or embeddings) for each input and compare them. Siamese Networks can be applied in use cases, like face recognition, detecting duplicates, and finding anomalies. Our goal is for the model to learn to estimate the similarity between images. For this, we will provide three images to the model, where two of them will be similar (anchor and positive samples), and the third will be unrelated (a negative example). For the network to learn, we use a triplet loss function.
Triplet Loss
Its introduction was first introduced in the FaceNet paper. TripletLoss is a loss function that trains a neural network to closely embed features of the same class while maximizing the distance between embeddings of different classes. To do this an anchor is chosen along with one negative and one positive sample.
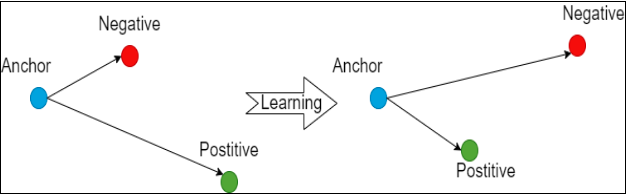 Figure: The Triplet loss minimizes the distance between an anchor and a positive
Figure: The Triplet loss minimizes the distance between an anchor and a positive
The loss function is described as a Euclidean distance function:

Here, A is our anchor input, P is the positive sample input, N is the negative sample input, and “margin” which you use to specify when a triplet has become too “easy” and you no longer want to adjust the weights from it.
Semi-Hard Online Learning
The best results are from the triplets known as “Semi-Hard”. These are defined as triplets where the negative is farther from the anchor than the positive but still produces a positive loss. To efficiently find these triplets you utilize online learning and only train from the Semi-Hard examples in each batch.
WorkFlow
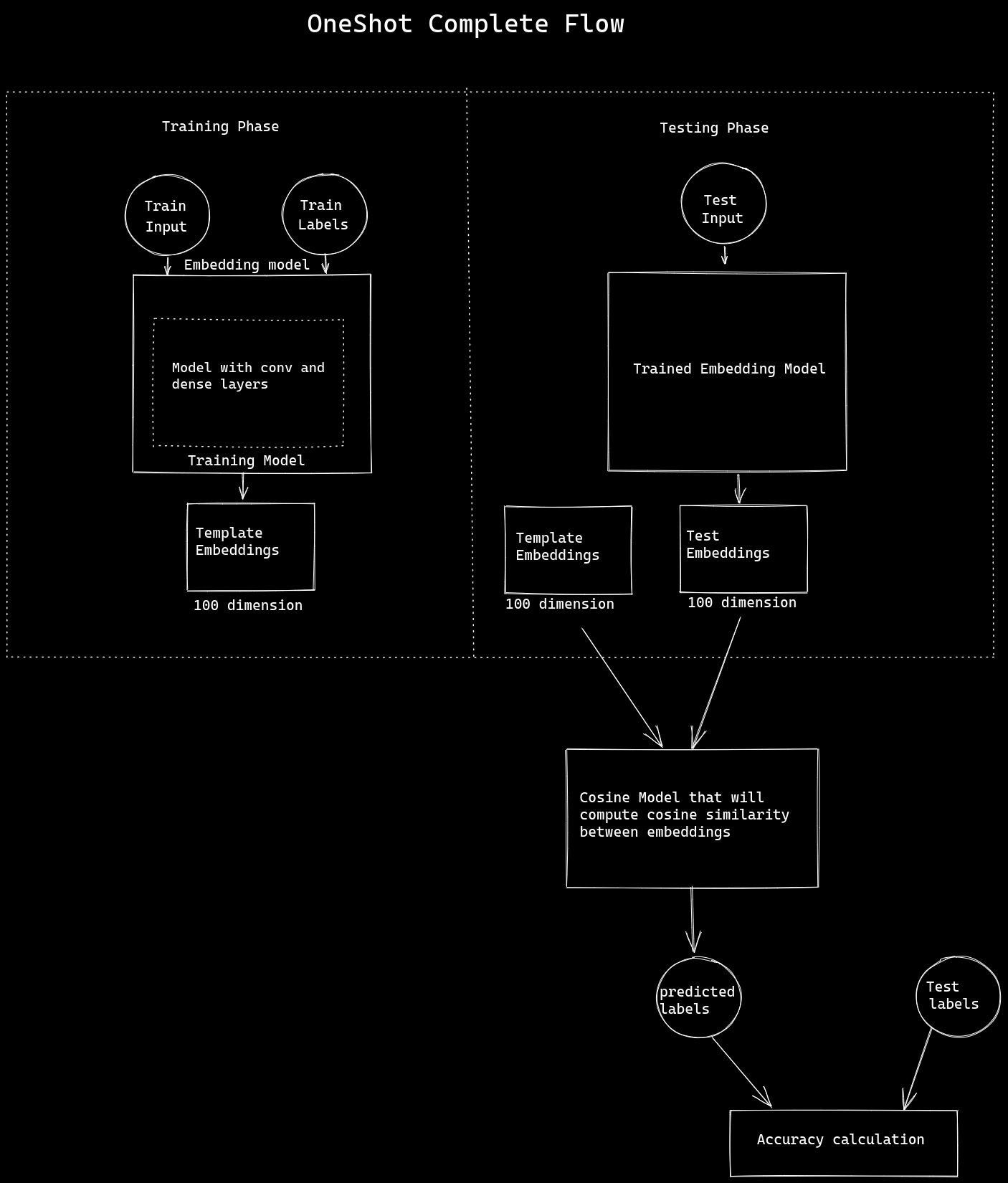
There are two phases in the flow of OneShot
1. Training Phase
- Here we will train our embeddings model
- This is how our embedding model architecture will be
- This is the embedding model that will be trained as mentioned above in the flow
- After training is completed we will save each digit’s image embeddings called template embeddings that will be used in test time
2. Testing Phase
- Here unseen data known as a test set is passed from the embedding model
- The unseen data after passing will now be converted to embeddings in n-dimensional
- The template embedding will be loaded and a custom generator is prepared
- The custom generator will generate pairs of embeddings of a test image and a loaded template model embedding
- The last step is to compare the pair embeddings
- To measure the similarity of pair we use a cosine similarity matrix
End-to-End examples for better understanding
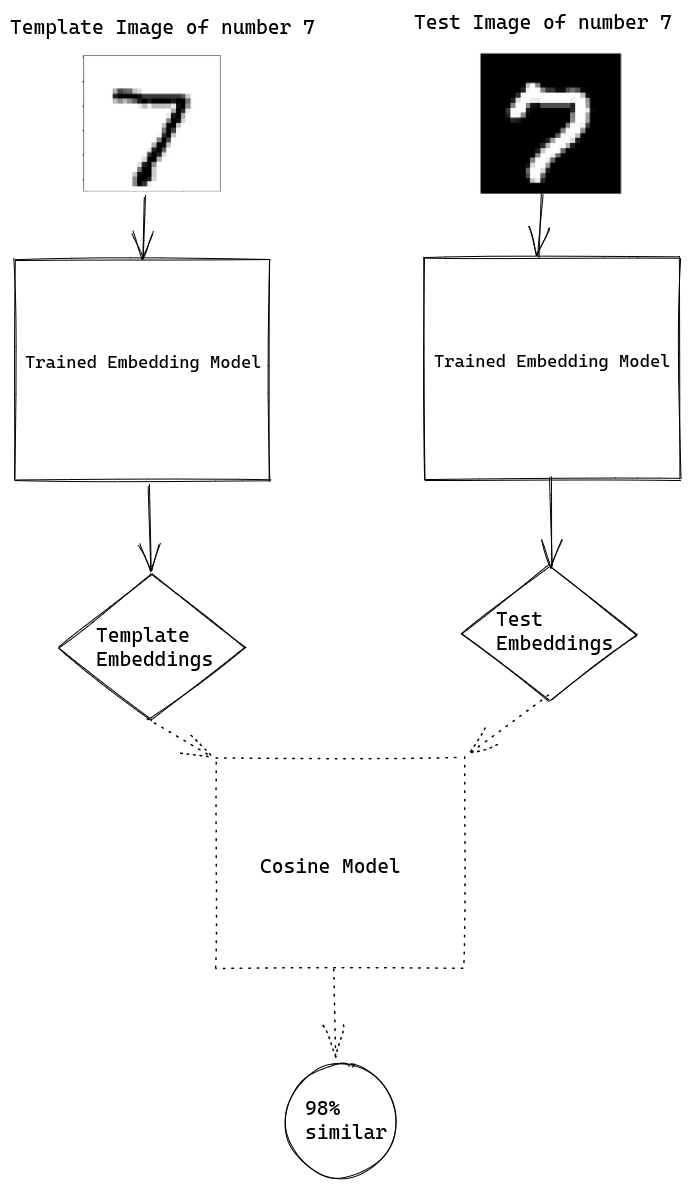
Example: Here is a testing image of number 7 from MNIST data. Here we got 98% similarity as both of the images represents the same number 7.
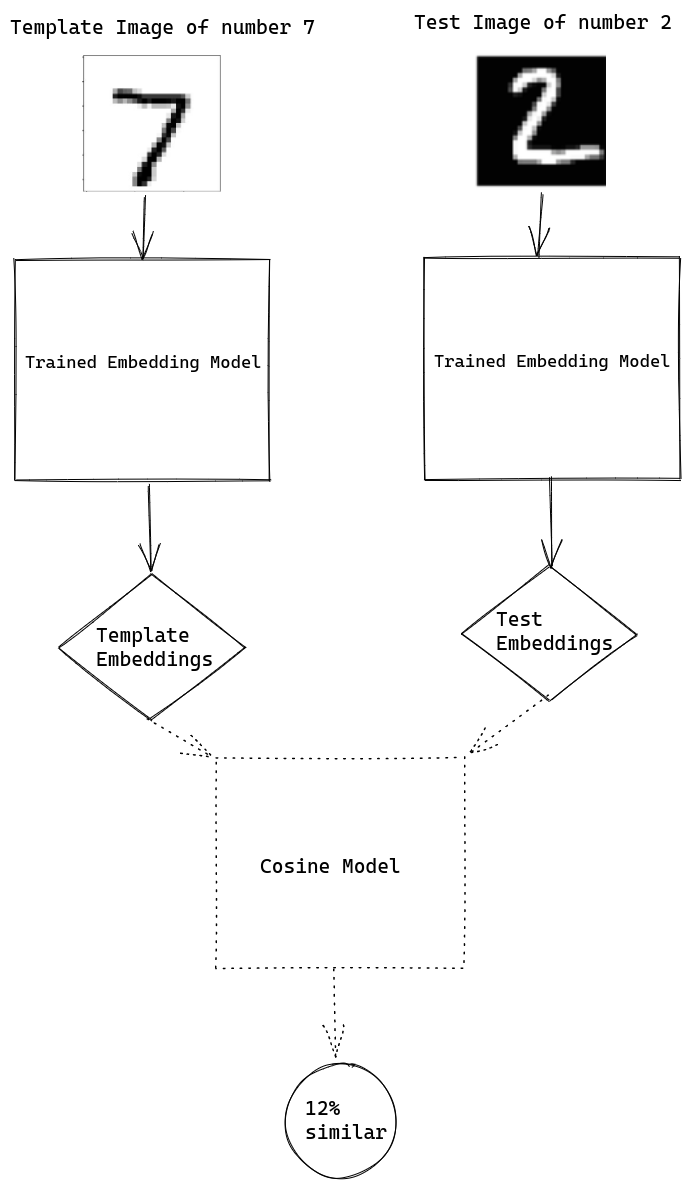
Example: Here is a testing image of number 2 from MNIST data. Here we got 12% similarity as one image represents the same number 7 label and the test image represent number 2 label.
Process of using OneShot learning models on unseen labels
- The best thing about one-shot learning is to use its powers on class or label that is not seen by the model
- A label that is unseen to the model can also be tested without taking into account the training for the particular model
- Here is the idea: we will not train the model on that particular label; instead we will use the trained model to compute template embeddings for the particular or unseen label
- The rest of the process will remain the same for that class during test time
- The test image of the unseen class will be compared to the saved embedding of that unseen class irrespective of training
The best example is attendance monitoring using the facial recognition of an institute. Just like many new students or staff joins the institute frequently, so should we retrain the model on each new face that comes to the institute to monitor the attendance. The answer is simply no we should not as we have the flexibility to save embeddings of a new face and during test time just compare it with that saved embeddings. This is just one use case for determining the role one shot in day-to-day life as many automated applications are also using it.
Conclusion
In the case of standard classification, for example, if we are trying to classify an image as cat or dog or horse or elephant, then for every input image, we generate 4 probabilities, indicating the probability of the image belonging to each of the 4 classes.
Now, during the training process, we require a large number of images for each of the classes (cats, dogs, horses, and elephants). Also, if the network is trained only on the above 4 classes of images, then we cannot expect to test it on any other class different from the given four. If we want our model to classify the images of a 5th class as well, then we need to first get a lot of images of that class and then we must re-train the model again. There are applications wherein we neither have enough data for each class and the total number of classes is huge as well as dynamically changing. Thus, the cost of data collection and periodical re-training is too high.