In this blog post, we will demonstrate how to perform custom training using the AWS Training Job service with xg-boost on a dataset. We will create our training job in four straightforward steps, enabling us to implement the entire process. By the end of this blog, you will be equipped to apply this technique, including preprocessing steps, to your own dataset.
Through this demonstration, we aim to provide a clear understanding of using AWS SageMaker for training jobs.
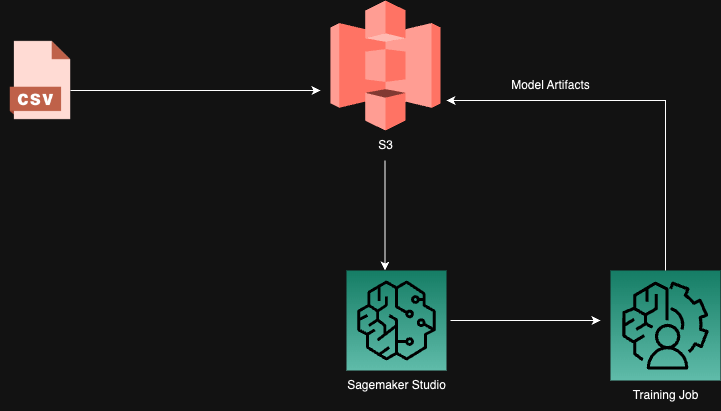
Why are AWS SageMaker training jobs essential for us?
We utilize a training script that currently operates in our local environment. However, AWS SageMaker training jobs offer two significant advantages over this approach. Firstly, they offer scalability by allowing us to utilize GPU instances or standard instances as needed. Secondly, they provide robustness by not relying on the stability of our local system. Even if our local system experiences issues such as crashes or log-offs, AWS SageMaker training jobs can continue uninterrupted and handle extended training durations because it is hosted over a cloud platform inside AWS. Building pipelines over it is a crucial necessity for machine learning engineers.
The upcoming implementation will involve the following steps:
- Uploading a CSV file to S3.
- Utilizing a training script to train a custom XGBOOST model with the uploaded dataset.
- Creating a notebook with an estimator to specify the file and instance type for the training job.
- Generating a model along with its logs and storing the artifacts in the desired location.
Let’s now delve into these steps to gain a comprehensive understanding of the entire process.
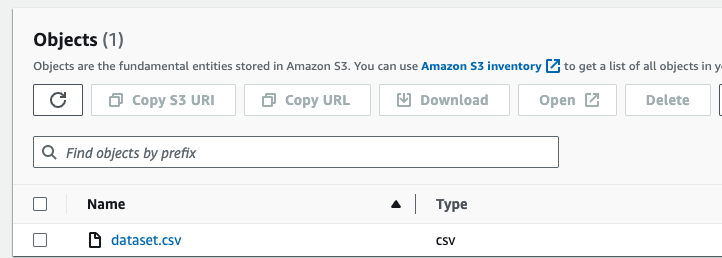
Step-1: Uploading CSV File to S3
In this step, we will upload the dataset we intend to train to the S3 storage. The dataset should contain two key elements:
- Input features: These will be preprocessed in the current blog but can also be managed during the training job at a later stage.
- Target variable: This is the variable we aim to predict, and its name will be crucial in the training script.
Step-2 Generate a Training Python Script in Sagemaker Studio
In this phase, we will craft a Python script as an entry point for the training job. This script will facilitate the interaction between the data and the machine learning algorithm, specifically XG-BOOST in our case.
The script will be named “train-job.py”.
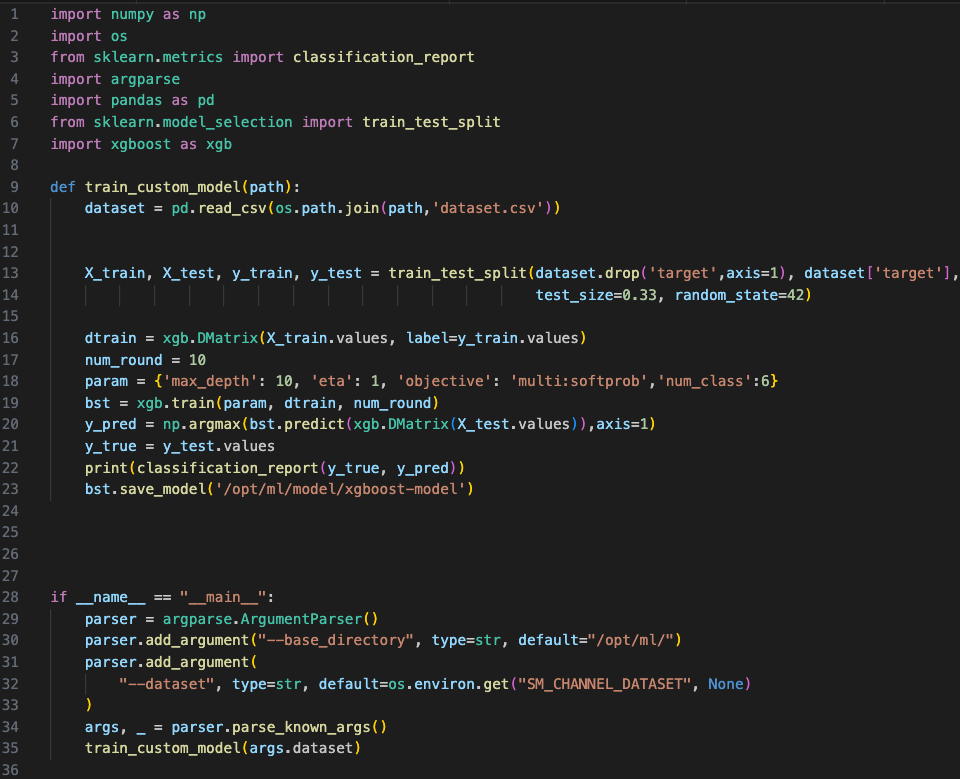
Let’s Attempt to comprehend this
In the main block, specifically lines 29 to 35, we map the provided dataset path to the corresponding argument. We then call a function responsible for training the model using the passed dataset, storing the output in the designated “/opt/ml/” directory.
Within the “train_custom_model” block, lines 9 to 23, the model is trained on a dataset named “dataset.csv” with the target column as the output. The dataset is further split into training and validation sets.
Once the training and validation processes are complete, the resulting model will be saved and made accessible after the training job is finished.
Step-3 Notebook Creation and Execution for Training Job
Proceed to create and execute the notebook dedicated to the training job.
estimator.ipynb
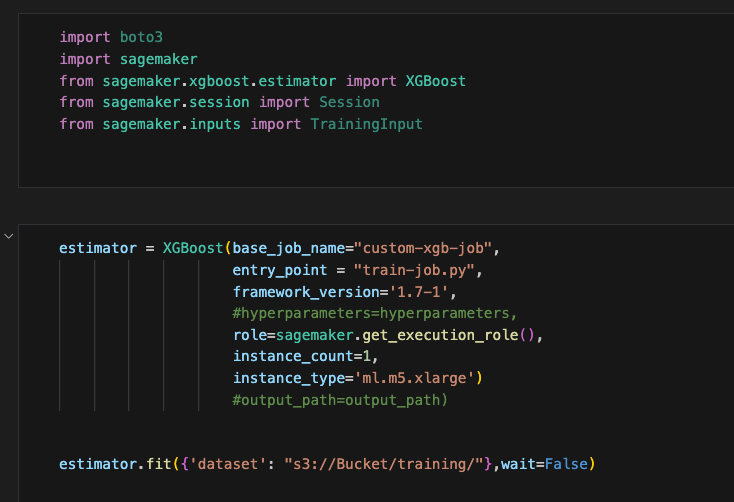
In this step, we need to define an estimator. We will pass the “train-job.py” script as an argument to the XGBoost framework, which will be fitted with the S3 path where we uploaded our “dataset.csv.” The “dataset.csv” file will automatically be selected in the step-2 file.
Furthermore, we will specify the instance type & count and provide a name for the job. It’s important to ensure that both the “train-job.py” and “estimator.ipynb” files are located in the same folder. If additional files are required, such as “requirements.txt”, you can upload them in a folder alongside the Python script, and then pass the source directory as an argument with the entry_point.
Step-4 Checkout training job, logs, and model artifacts on AWS
Upon executing this notebook, you will observe the job actively running in the “Training Job” section within Amazon SageMaker.
![]()
![]()
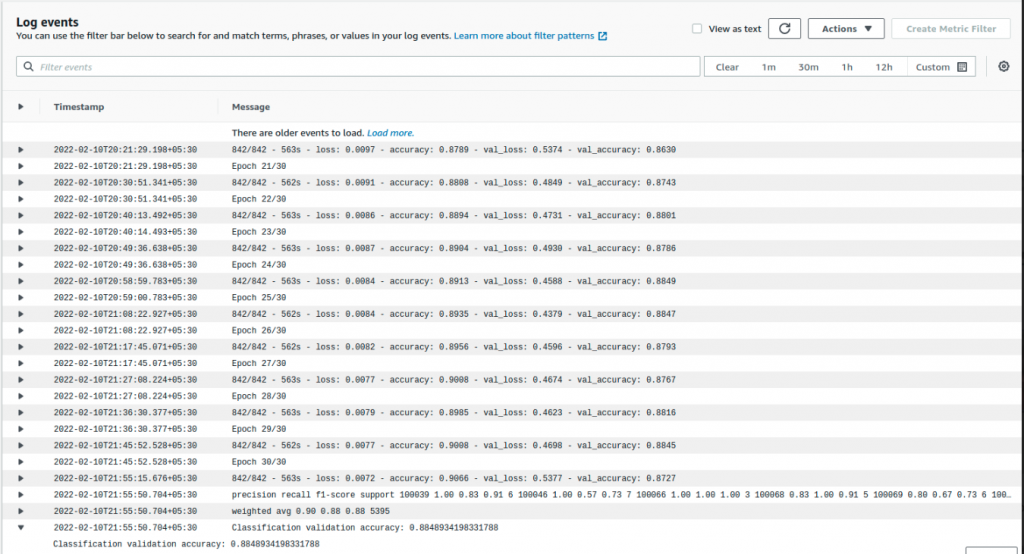
Logs like these can be accessible in the training job
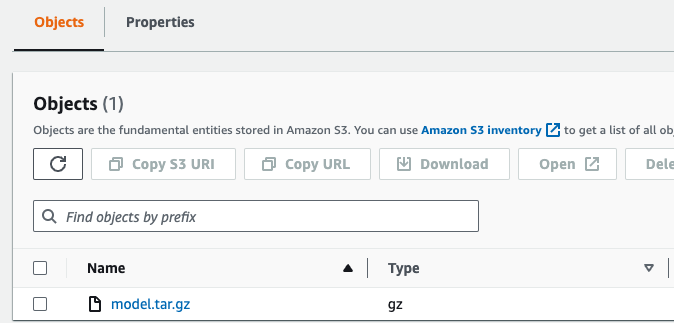
The training job will produce saved model artifacts, allowing you to reproduce the results. You can locate these artifacts within the training job as an s3 path, ensuring that the “train-job.py” script specifies the output or saves the path name as “/opt/ml/model” to create the tar file.
The AWS Training Job offers several advantages, making it a powerful tool for training machine learning models:
- Scalability: AWS Training Job allows you to train machine learning models on large datasets and complex models by leveraging the scalable infrastructure of Amazon Web Services. This ensures you can efficiently train models regardless of the data size or complexity.
- Cost-effectiveness: AWS Training Job provides a pay-as-you-go pricing model, enabling you to pay only for the resources you use during the training process. This cost-effective approach allows you to avoid upfront infrastructure costs and easily manage your training budget.
- Flexibility: AWS Training Job supports many machine learning frameworks, including popular ones like TensorFlow, PyTorch, and XGBoost. This flexibility lets you choose the framework best suits your project’s requirements.
- Auto Scaling: With AWS Training Job, you can configure auto-scaling for your training jobs, automatically adjusting the number of training instances based on the workload. This ensures efficient resource utilization and faster training times.
- Distributed Training: AWS Training Job supports distributed training, allowing you to distribute the training workload across multiple instances, which can significantly reduce training time for large-scale models.
- Monitoring and Metrics: AWS provides tools and services to monitor and track the training job’s progress and performance. You can access real-time metrics, logs, and visualizations to gain insights into the training process.
Conclusion
In conclusion, AWS Training Job offers a comprehensive and efficient solution for training machine learning models on the cloud. Its key advantages include scalability, cost-effectiveness, flexibility, auto-scaling, distributed training, monitoring and metrics, easy model deployment, security, and integration with other AWS services.
AWS Training Job empowers data scientists and developers to efficiently train machine learning models, enabling them to focus on model development and optimization and ultimately accelerating the deployment of innovative and data-driven solutions.
Pricing resource – https://aws.amazon.com/sagemaker/pricing/